
how i think about and use AI : part two - looking inside
not magic

note: this installment includes a number of images, increasing the total file size of the email. if your email client truncates the post because of this, you can read it in its entirety on skidmore.substack.com.
in part one of this series, we looked at my framework for thinking about modern AI tools, particularly these magical chat bots like ChatGPT or Grok that seem so knowledgeable and helpful (when they’re not just making things up).
you can read that here:
how i think about and use AI : part one - bicycles, centaurs, and you

“any sufficiently advanced technology is indistinguishable from magic.”
but what are these chat bots, anyway? what are they doing? how do they work? should i trust them? why do they make up stuff? what does it really know?
this is what we’re looking at today. this is going to greatly oversimplify some technical understanding of these tools, so if you’re a tech bro, don’t @ me. i’m just trying to help more people understand.
but despite venturing into some technical territory, my main goal here is to show you that there’s no voodoo happening. just math. and based on that, what you can expect and not expect these chat bots to accomplish. this will allow you to venture into using these tools without “spooky fear”. instead, you can see them as tools for certain things, and you — fledging digital centaur — can make use of them in ways that help you do your work — a bicycle for your mind.
how do they work?
ChatGPT, Grok, and other similar chat bots are officially known as LLMs — Large Language Models.
LLMs
let’s begin with a sort of visual analogy, then we’ll get closer to what’s really happening under the hood.
let’s start with letters
imagine the 26 letters of the alphabet. now imagine them on two axes, vertical and horizontal. so on the vertical, you have all 26 letters, and on the horizontal you have all 26 letters.

this forms a grid, a graph, of all possible letter combinations. AA, AB, AC and so on across the top, down the side you'd have AA, BA, CA, etc.

now each box is numbered, like the periodic table, so that each box has a unique number.

now we’ll go through an English-language dictionary and take every word in it, all ~200,000 of them. this will be our training material. we’ll go through two letters at a time, and every time we see a combination, we’ll put a tick in the respective box on our chart.

so for the word “aardvark”, we’d see “AA” and put a tick in box 1. then “AR” and put a tick in box 18. then “RD” and “DV” and so on. and we’d do this for every word in the dictionary. when we’re done, we’ll tally up the number of ticks in each box.
now each numbered box has a score, which is the percentage chance/likelihood of that combination appearing in any given English word. so you can imagine the combination AA would have a low score, but not zero (as in "aardvark") whereas the combination AB would have a higher score (about, abnormal, abscess, and more).
if you had this chart and i gave you the first letter of a word i'm thinking of, you could take an educated guess at what the next letter might be. but to really work well at guessing whole words, our chart would need more than two axes. “DV” wouldn’t appear at the beginning of many words (Dvořák, maybe, if it were in our chosen dictionary) but would appear more often inside a word (“aardvark”, “adverb”, “advent”, “advertisement”). that means we need more than one score, scores the depend upon the chain of letters preceding. so two axes are fine for two-letter words, but we’ll need three axes for three-letter words (AAA, AAB, ABA, BAA, ABB, BAB, BBA, BBB, etc.), four axes for four-letter words, and so on.
soon, all of these axes becomes confusing as a chart, so a better layout would be a neural network, like a flowchart, or a family tree or like a schematic drawing of all the computers on the Internet. an ever-diverging web of connections. start with one letter, and all possible next letters emanate from it. from those secondary letters, all possible third letters of three-letter combinations, and so on.

if this were all laid out on a big sheet of paper, you could trace a path with your finger from the beginning to the end of the word. in fact, any path you trace, no matter how random, would produce a word found in the original dictionary we used. the scores — the tick marks from before — now reside on the connection between letters. these scores are called weights. the complete database cataloging these weights is called the model.

in the photo above, we’ve trained this model on only 7 words: access, accessory, accessoried, accessories, accessorize, accessorized, and accessorizes. as we go through the letters, we pass “ACCESS” 7 times, so it has a heavy weight. all the other words follow with “OR” so we pass through that connection 6 times, etc. you might also say, “um, i don’t think ‘accessoried’ is a word.” but the model doesn’t know that. the model (in this case) is a sheet of paper. it doesn’t “know” anything. “accessoried” is in the training material, so it’s in the model. the point here is: errors go into the model via the training materials, errors can come out.
same thing, but with sentences
now imagine that big neural network, but instead of using a dictionary (list of words) as the material from which we tally up our scores, we will use billions of sentences — books, articles, blogs, etc. these are our training materials. so every time a word pair or phrase or sentence appears in the training materials, it adds weight to that connection of words in the model we’re building.
and now we arrive similarly at a neural network, one capable of producing phrases, sentences, paragraphs. pick a starting point, and trace connections, and you’ll end up with a coherent sentence of some kind, or perhaps an entire poem or essay or chapter.
plinko
imagine if this neural network were made by carving into an giant upright slab of wood. every time you read a sentence in the training material, you’d carve a path for those letters with a box cutter. and all of these paths would go from top to bottom, creating a giant custom Plinko board.

the more times you passed a phrase or sentence, the wider the channel would get. so the phrase “octopus britches” would be quite narrow, as i’m not sure that phrase has ever been in print until just this second. but the phrase “by the way” might be quite wide, as it would like appear many times. a phrase like “life, liberty, and the pursuit of happiness” might be wide as well, depending on your training materials. surely, the Declaration of Independence as a document would only appear once in your training materials, but there would likely be many references to it in text books, song lyrics, photo captions, what have you. the widths of the paths are the weights.
so if i gave you a sentence i’ve written — called the input— you could find that on the board to use as a starting point. if you were to drop your Plinko puck into that input, it would fall down the larger paths, creating new sentences as it goes. following the heavier weighted (wider) channels will ensure the path produces a coherent response — the output — related to the input. and the output would seem to be a response, because it is beginning from connections related to the input ("bank" near "money" would lead you down one path of the matrix while "bank" near "river" would lead you down a different one).
even if it’s a sentence that no one has ever written before, the output you’d receive exists because of the weighted connections in the model derived from the training materials. the model is not “writing” anything, merely tumbling down these weighted paths and delivering the output to you. it’s a similar mechanism as the predictive text feature on your smartphone keyboard.
and again, i must point out, whatever is in the training material determines the model. if there are spelling and grammatical errors in the training material, that goes in the model. if a document is in Spanish, that goes in the model. if some hate mail or smutty romance books are part of the training material, that goes in the model. the model does not discriminate. it cannot. it is not “alive”, it’s not a person. it is just software and math.
further confusions
in fact, the LLM models don’t operate with letters or words. it turns your words and letters into “tokens”, basically the “periodic table number” of the letter/word combination. so the LLM is not really dealing in text at all. it’s just a giant database of numbers and their connection to each other. the hardware-accelerated software engine that translates input to tokens to model to tokens to output is called a transformer. the transformer trains on the training data to build the model. then the transformer takes your smaller inputs, runs them through the model, and provides your outputs.
and here’s one that will make your head explode:
because the models are pre-trained, the model “contains” every possible answer it could ever give about anything before you ever ask it a single question.1 not to say that the actual answers and responses are in there, but the possibility of them is in there.
and to clarify: these models don’t have all the answers to everything, only the answers made possible by the training material.
this is also why they often “hallucinate”, that is, return bad outputs, just make up stuff. the LLM isn’t “wrong”. it is simply just spitting out words based on the model. it might give you a youtube link that is broken or goes to the wrong video. it’s not because it has old or bad data, but because in its training materials there are lots of youtube URLs, and youtube URLs have a standard format. so it generates something that looks like a youtube URL the same way its other outputs are something that look like a sentence.
modern LLMs have all sorts of tools added to them to help fact check or provide guardrails against inappropriate outputs, but this isn’t the model knowing things. the model is just software. no knowing. artificial intelligence. it’s just mimicking all the writing it’s seen before.

summary
anyway, this is — in a very oversimplified way — what a modern LLM is doing. it takes your input text and turns it into tokens. based on your string of tokens, it heads down the most likely neural path — pulling what is most likely the information requested — and dumps its own tokens out as an answer, which are then translated back into text.
the model doesn’t “know” anything and isn’t “thinking”; it’s doing math with an extremely large table of data.
GPTs
the GPT in ChatGPT stands for Generative Pre-trained Transformer. a GPT is a type of LLM, specifically developed by the company OpenAI.
the Transformer trains the model, turns text to tokens, turns tokens to text, and turns your inputs into outputs by tumbling through the model.
the Pre-Trained part means the Transformer model has previously analyzed those billions of sentences in order to “learn” and create those mathematical weighs, ready to be used when you call on it.
when you input a query or prompt, the Transformer quickly analyzes and assesses your input to compare to the pre-trained model, and then generates (the Generative part) the output, a new string of text as a response.
Claude by Anthropic, Google’s Gemini, and Grok from xAI are not GPTs (as that’s a proprietary term to OpenAI) but they function in the same way. a transformer engine, pre-trained model, and a decoder to generate a chat-like experience. the broader term is “decoder-only transformer language models”.
but just calling them GPT-like is easier. kind of like how here in the South, all sodas are just called Coke.

each GPT or GPT-like model has different strengths and weaknesses. Grok is connected to real-time data (posts, news, reactions, etc.) from 𝕏. Claude better handles extremely long chats (called contexts) like analyzing or composing large documents. and each iteration of each model has a better developed transformer (upgraded software) and is trained on a better and/or larger set of training data (upgraded model). at the time of this writing Grok is on version 4, with Elon already touting how good 5 is gonna be. ChatGPT just released ChatGPT 5 a few weeks ago. every week, seems like there’s an upgrade to something, or some completely new tool hitting the market.
non-text AIs
not all generative AI deals with text. some generate images, video, computer code, music, speech, and more. but they are trained in the same way, and they generate their respective media in the same way.
get a bunch of images (tagged with metadata about what it’s an image of) and let the model analyze them; now you have a text-to-image model. if the tag is “cat”, and this pixel is blue-gray, what are the pixels next to it most likely to be? do this over and over, and you get an image of a cat. not a cat that was in the training material, but a new image derived from what most cat photos look like. this generates a photo output from a text input.
train on a bunch of melodies. if the first three notes are C, Eb, E natural, what’s the most likely 4th note?
train on a bunch of videos, then use a still image as input. based on the information in the input image, how will those pixels likely shift over time, based on the training data? this creates video outputs.
train on speech. it’s about what sound waves are likely to occur one after another. by the way, this is the odd thing about some of the speech models. you may think it is converting your speech to text, then doing the ChatGPT thing with it, then converting the text output back into speech. some do work that way. but some of the most popular ones (like ChatGPT’s Advanced Voice mode) do not. it is a speech model. it converts the sound waves of your speech directly to tokens. the model is trained on hours of recordings of human speech rather than billions of text sentences. the output tokens are converted to sound waves. the newer, more sophisticated models will convert the audio to text to put text versions of your speech and ChatGPT’s speech in the chat for your convenience. but the speech models do not work on text or words, just the sound wave patterns of speech. which is a little bonkers to me. but anyway that’s why you get a very different tone/style of answer (and sometimes different content of answer) from the speech models as opposed to the text models.
and some models, like ChatGPT 4o (and now also 5), are called “multimodal”, meaning they are capable of multiple modes of generation — text, speech, images, code… whatever is called for.
ethical caveats
one note, something you might be asking. a model is only as good as the data upon which it trains, but where does this training data come from?
this is a very important question without a lot of easy answers, so i will only touch on it. it’s not really the topic of these posts, but it also can’t go unaddressed.
training concerns
these Large Language Models train on billions of sentences, most scraped from the current public Internet, meaning much of it contains copyrighted materials — blog posts, ebooks, an artist’s photographs, YouTube videos, etc. if you can find it on the Internet, it has potentially been scraped for training, possibly even your own website, blog, or social media accounts.
the views and arguments are complex, but to (once again) greatly oversimplify, i will suggest a spectrum.

at one end is the person who says, understandably, “you ingested my copyrighted work and made money off of it without my permission and without compensating me. that is unethical and is/should be illegal.” at the other end is a counter-argument that goes something like, “if you go to college or a library and learn things from books or from looking at art or from listening to music, then you create books, art, or music of your own, how is that any different?” while the end result of these two lines of thinking may appear opposite, the arguments are not really opposite. they are inclined to opposing behavior by different concerns, but each has valid reasoning. legally, it comes down to specific issues about consent and licensing, but ethically and philosophically, it’s a lot more gray than it seems at first.
i’ve written this entire post by thinking it up with my mind and typing it with my own fingers — no LLM assists used in its composition, not even idea generation or editing2 (it would probably be shorter and more coherent had i used it).
and yet everything here is an amalgam of information i’ve gleaned from dozens of sources, some long forgotten, many of them copyrighted. few of them did i pay directly for or inquire to the author in hopes i might one day repeat an idea it gave me. there’s no works-cited at the end of this (though i do explicitly link to direct information if i am specifically regurgitating it and can find the original source). and i have paid subscribers. so am i being unethically paid for amalgamating a bunch of text and photos into a new text and photo compilation that is meaningful to a new group of people in a new way? or is that just… how we do everything in life all the time?
Fair Use?
here’s a more specific example. in this article as well as the part one, i used a still image of HAL 9000 from 2001: A Space Odyssey. i don’t have permission or license from Harry Lange (production designer) or Geoffrey Unsworth (the cinematographer) or Stanley Kubrick or MGM to use it. MGM could come along an issue a take-down request or send me an old-school cease-and-desist letter.
but if i were to fight it in court, i would likely win on the Fair Use principle of copyright law. Fair Use is loosely defined, but four things are taken into account:
what percentage of the original work is being used?
what percentage of the new work is comprised of the portion of the original work?
is the nature/meaning/usage of the original work being changed by the new work?
is the new work preventing the old work from making money?
so with my use of the 2001 images, 1) the other person’s copyrighted work that i’m using is a small part of their work (a few frames out of ~214560 frames in the whole film); 2) the images are only a small part of my work; 3) it’s being used in a new and changed way (a visual aid for education… you’re learning something, right?); and 4) it’s not taking any money away from them. this ticks the four main boxes for Fair Use. and at the end of the day, what’s most likely to happen is for someone to see the image and think, “you know… i haven’t seen 2001 in a while…” and fire it up on their nearest device. so i’m likely to not receive any such pushback from MGM as it simply wouldn’t be worth spending their resources.
and likewise, many of the AI companies have used a Fair Use explanation in defense of their training content practices. but given they are dumping billions of dollars into these new endeavors, copyright owners are more motivated to press the issue out of Fair Use territory. after all, the training models 1) may use all of the copyrighted work, and 2) may serve up any or all of its information or ideas or style at any time, 3) replacing its exact intended purpose, 4) resulting in no need to buy the work. that pretty much violates all four Fair Use principles.
and then we ask ourselves how much of our current technological experience is because Google takes whatever information it can with ethically-questionable methods, or because Steve Jobs ripped off ideas from Xerox, or whatever. are those things my fault? i just need to use a mouse, or send a spreadsheet, or learn to use nodes in Resolve. what’s my ultimate responsibility in all of this? i’m just trying to do my work.
look, i’m genuinely not trying to confound, or “did God really say..?” the situation. there are some clear legal lines we can and will draw. there are some ethical practices that will eventually be developed.
but right now, it’s kind of the Wild West. so you can start panning for gold or you can stay home until the ethical infrastructure is more developed.
and in their defense, i decided to let the LLMs speak for themselves. since they’re trained on all the articles and posts about the issue, they’re naturally pretty open and honest about it:

good stewardship
there’s also a lot of talk about the vast resources it takes to train and operate this models. there’s currently billions of dollars flying around. individual developers are being offered hundreds of millions of dollars. a lot of this money is sort of monopoly money — inflated investments, small amounts against big amounts to come later, etc. but even with that factored in, there’s a lot of money changing hands.
in addition to money, it takes massive amounts of power to run the training computers and then the servers that transform your inputs into outputs. that power has to come from somewhere. and those servers generate heat that has to go somewhere. and when those GPUs are out of date (every year? every 6 months?), how do you dispose of them in favor of the new ones?
i’m not qualified to get into the specifics of the financial and environmental conundrums. but i sum up all this resource usage under the theme of “stewardship”.
doing new things uses up resources, just like doing the old things (cars, planes, televisions, telephones, electricity). solving problems creates new ones. but if we can learn to be good stewards of what’s in our hands and the ways we can incentivize others to be good stewards as well, i think we’ll make it.
dissenters
lastly, i’ll share an opposing voice (among many). search 𝕏 for “@justinebateman AI” and you’ll see some of her colorful opposition. this recent post sums up her general opinion regarding AI, but her strong views go back years, all public on her feed. she… does not hold back.
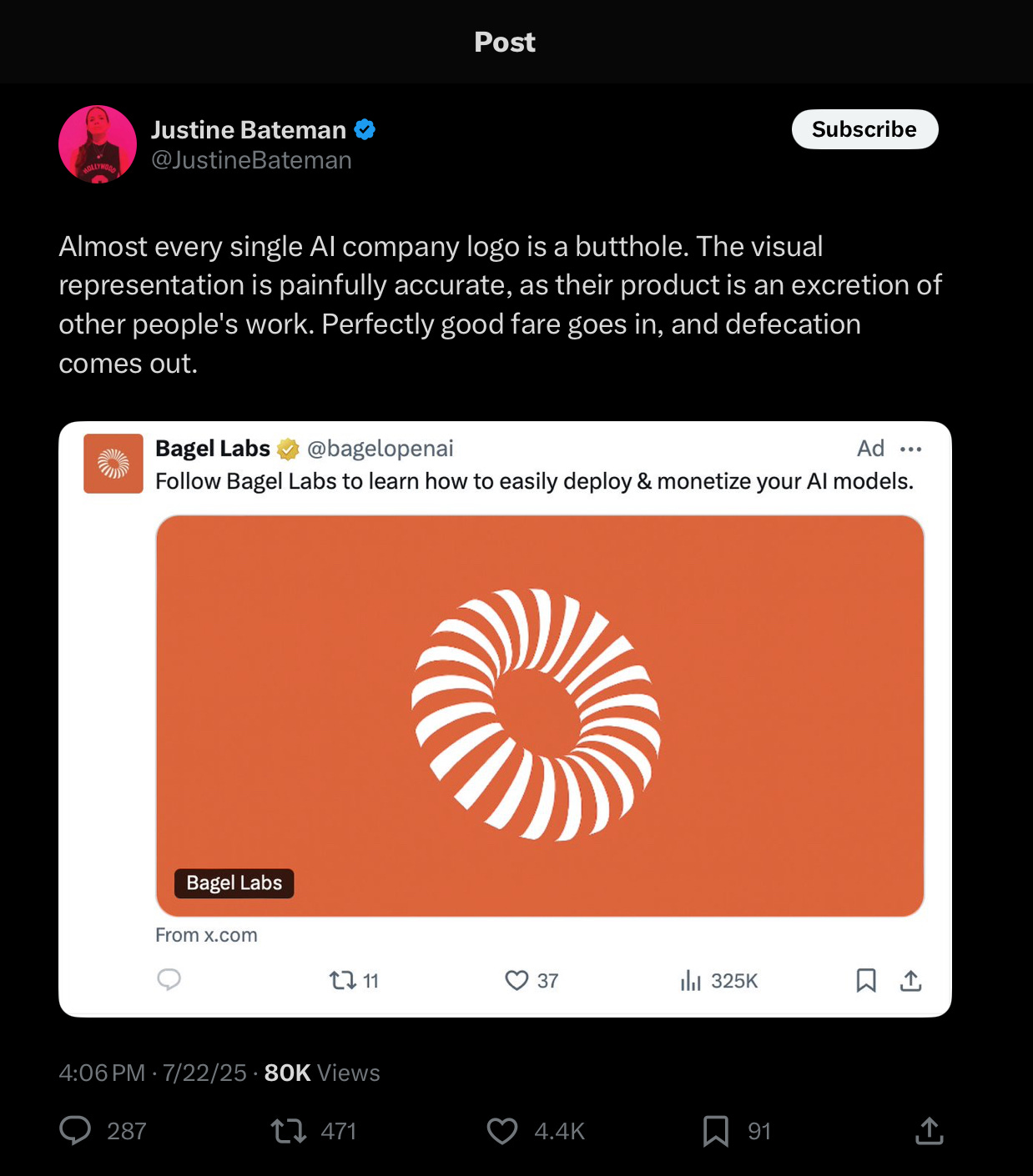
i give you this one dissenter because she quite adeptly sums up a lot of the arguments against using AI at all for any reason, and certainly against some of the popular applications of it.
and… i agree with many of the opinions of dissenters, actually. it goes back to stewardship, and the idea that any technology can build up or tear down.
AI is here to stay. we have to find our way. the clothes you’re wearing, the food you ate today, the device you’re reading this on — if you saw the complete supply chain for these you’d likely be shocked and horrified at some of the things that happen along the way. each of us has to figure out our ethical boundaries, make our own choices, redeem and repair when and where we can, and navigate an unethical world to do our work as ethically and responsibly as possible.
anyway, on with show.
coming up
in part three, i’ll start actually sharing how i’m using AI, and how you can use it, too. so stick around for the good stuff.
modern LLMs are connected to the Internet and other tools that allow them to expand their “knowledge”, but we’re just talking about how a base LLM model (no tools) works here. again, greatly oversimplifying. but download a trained model, and you can run it on a device with no Internet connection, and it will still have all the same answers, because they’re baked into the data in the model. it will just take longer to do the transforming, depending on your local processing power and RAM.
i did run a near-final draft through several LLMs for fact-checking. and of course a couple of the images are generated.
at the time of the original research for this article, ChatGPT 5 had not yet been released.